
The bus factor problem
How to resolve it and build a resilient team

A team that can’t survive a two-week vacation can’t scale its impact. Your team’s knowledge shouldn’t have a single point of failure.
In this week's issue, I will share tactics for sharing information within the team and turn the bus factor situation into a resilient, improved team.
If you don’t know me, my name is Roman. I lead the engineering organization at a startup and help engineering managers and leaders build resilient, high‑performing teams. Each week, I share one practical idea you can apply right away with your own team.
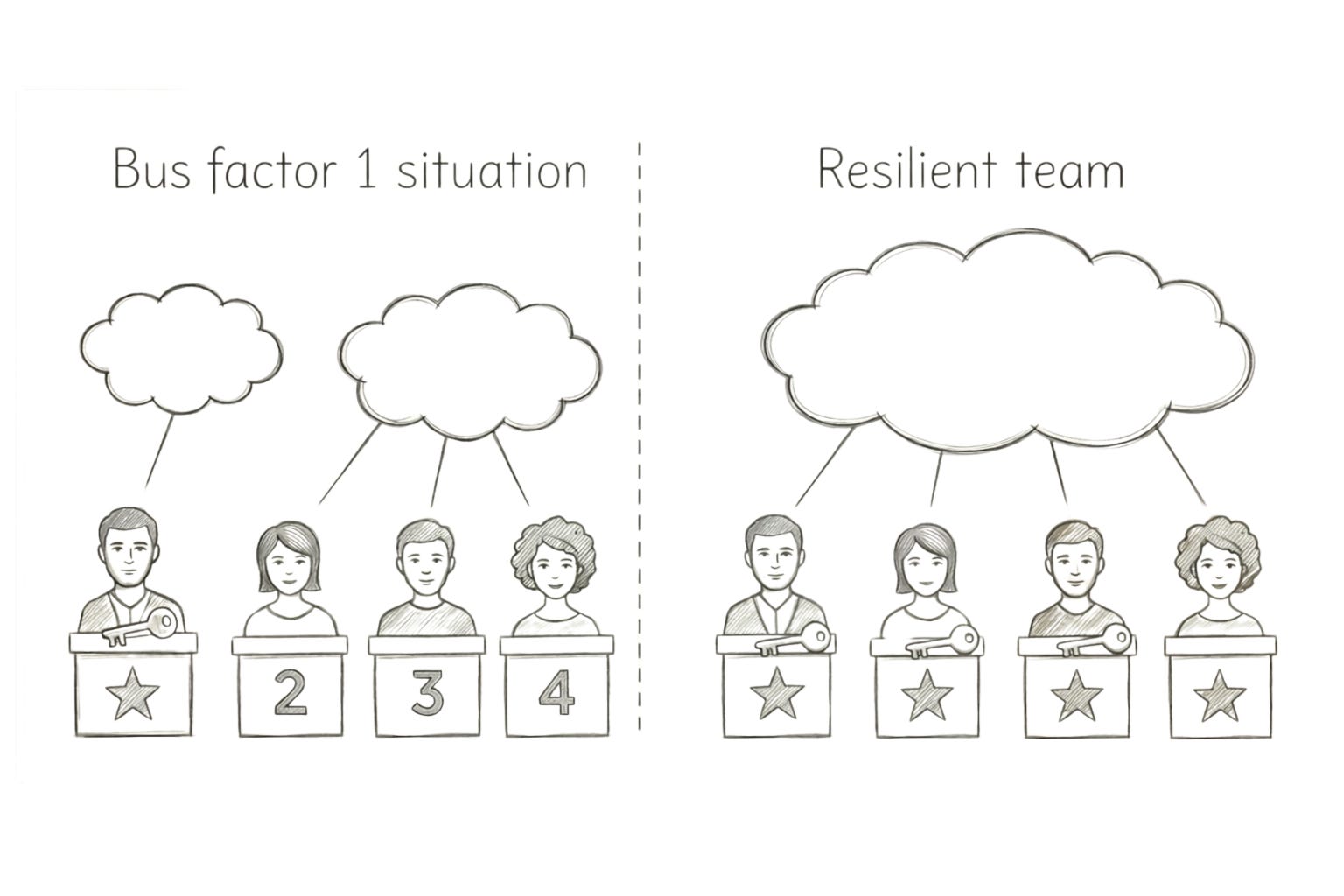
A silo in the team
We all have been in teams where we had a star contributor. They are someone super-talented and fast. They worked on the project from the start and know the architecture better than anyone else. They are respected, reliable, and trusted. They save the day when pressure is high, and then production is on fire.
It is typical and problematic for several reasons:
Star contributor owns some areas of the system end-to-end. The bus factor is one. If they go on a long vacation or leave tomorrow, no one can support this code.
The star is a bottleneck. With all their brilliance, the star sometimes gets overwhelmed. There are too many tasks in their area of responsibility, and no one can provide help effectively.
You limit the impact of your start contributor. Instead of leveraging their knowledge, developing the team, and contributing to the new code, they are often stuck with supporting older parts of the system.
How to break the silos
The fix is deliberate knowledge distribution, even when it feels slower in the short term.
Rotate people on tasks. If Alice has owned the billing integration since day one, she’s fast — but the bus factor is one. Have her document the process, then assign Bob to do it next using that documentation. When Bob hits gaps, he asks Alice and updates the docs. The time after that, Carol takes the task. Within a few cycles, three people can do what only one could before.
Rotate on-call and support duties. Being responsible for a system in production is one of the best ways to learn how it actually works. When someone new joins the on-call rotation for a service they didn’t build, they naturally pick up operational knowledge that scheduled knowledge transfers often miss. This also pressure-tests your runbooks and documentation — if the on-call person regularly needs to escalate to the original author, that’s a useful signal that knowledge distribution has more ground to cover.
To make this safe, don’t throw people straight into the deep end. Start with a couple of shadow on-call shifts, walk through real incidents together using the runbook, and only then put them on primary with a clear escalation path if they get stuck.
Pair people on projects. No one does a large task that takes weeks alone. People split the work and collaborate as a group. This will sometimes be slower than letting one experienced person handle it end-to-end — accept that tradeoff. The goal isn’t maximum speed on this task. It’s building a team that doesn’t collapse when one person is unavailable.
Treat documentation as real work. Create a ticket for it and prioritize it like any other deliverable. Run a Q&A session afterward to surface what’s still unclear, then update the docs. Documentation that lives only in someone’s head isn’t documentation.
The upfront cost is real, but it’s a one-time investment per area. A bus factor of one hurts continuously until it’s resolved.
Hoarding information
There is a darker side to information siloing: intentionally hoarding knowledge to protect one’s position.
The core advice — rotate, pair, document — still applies here. But with an active hoarder, the process itself becomes the battleground. They volunteer to “help” so much that the other person never learns independence. The documentation is technically present but practically useless. The pairing session turns into a demo where one person drives and the other watches.
This means the manager has to go beyond setting up the process and actively verify the outcomes. Rotation isn’t just “Bob does the task next quarter.” It’s “Bob does the task independently, and if he can’t, I need to understand why the handoff failed.” That accountability is what turns a process into an actual solution.
When subtle resistance continues, name the problem directly and privately. Lead with curiosity — “I’ve noticed you’re still the only person who can deploy this service, and that concerns me” — but be clear about expectations going forward. The team cannot be held hostage by one person’s leverage, and tolerating it signals to everyone else that hoarding is a viable career strategy.
On a positive note, information hoarding is losing some of its power. AI coding agents can now analyze and reason through large codebases in seconds, which significantly reduces the leverage a single knowledge-holder has over the team. It doesn’t eliminate the problem, but it makes the “I’m the only one who understands this” position harder to maintain.
Let your star shine
Your star contributor might be stuck maintaining code that only they fully understand. By distributing that responsibility across the team, you free them to do higher-leverage work — mentoring, contributing to architecture, helping the whole team level up.
This reframing matters for the star themselves. Presenting the change in terms of a bigger impact and growth, rather than “building redundancy,” makes it easier to embrace and even desirable. Most strong contributors don’t want to be the single point of failure forever — they just need to see a path forward that doesn’t feel like giving up what made them valuable.
I wrote more about investing in star contributors (multipliers) here.
Final thoughts
Building redundancy and resilience in a team is not a quick fix. Training people on the darker corners of the system will hurt velocity in the short term. But it’s an investment that pays back many times over.
A team where knowledge is shared is a team that can absorb surprises — someone leaves, a critical system breaks during a vacation, priorities shift suddenly. These things stop being emergencies and start being manageable events.
And the benefits go beyond risk mitigation. We don’t only share information. We level up the whole team. People grow faster when they’re exposed to unfamiliar systems. Stars get freed to do their best work. Junior engineers build confidence by owning things they couldn’t have touched before.
The manager’s job is to make this happen even when it’s uncomfortable — to slow down today so the team can move faster tomorrow.
That’s all for today.
Have a nice week,
Roman
P.S. Scaling an engineering org is hard — especially without a sounding board who’s been through it. I help engineering managers, engineering leaders, and startup founders stress‑test their strategy and scale their teams without repeating the usual mistakes. If you’re facing a challenge around org design, technical leadership, or growth, drop me a message on LinkedIn.
It’s a great approach to create an anti-fragile team.
From the experience, I know how hard it’s in practice. There is a strict deadline, management interferes and asks to assign the star player to the project to be on time. Company priorities overweight the importance of knowledge distribution.
But that’s life. Even if these rules can be implemented 70% of time, it’s already a win.
One more additional technique I employ to flesh out info is to religiously do teams recordibg of various reviews, architectural , reverse knowledge transition of recently on boarded team mates, prototype walk throughs etc.
These videos can easily be digitized and stored for future easy reference by anyone.
Ps. This task can be easily accomplishable using ai tools.