
Addressing the code review bottleneck
Basic habits, advanced AI, and when to skip the review altogether


The biggest improvement we made to code reviews was rethinking when a human code review was actually necessary.
Code reviews have been a bottleneck for the team for as long as I can remember. Writing code was relatively fast, but then changes got stuck in code review for days.
There are multiple reasons for this, but the main one is that people need to do their own work. They don’t sit idle waiting for me to open a pull request before jumping on it.
Even if the first review goes through quickly, the person who raised the PR needs to address comments and wait for another round of review. Every handover takes time. This is a typical symptom of a long feedback loop.
Feedback Loops
Feedback loops are essential in any type of creative activity, including software engineering.
Some feedback loops can be easily automated. For example, code syntax checking. Building software is so fast in most cases that syntax checking takes seconds. After that, the operator — human or AI agent — can continue working on the task.
An example of a slower feedback loop is CI. A typical continuous integration pipeline takes minutes, and in some cases, tens of minutes. The developer either has to wait patiently or switch to something else in the meantime. This leads to a loss of context and flow.
In both cases, the feedback provider is a machine. In the case of code review, it is another human.
That makes the process much slower.
People are not good at multitasking, context switching hurts, and understanding the intent of code requires mental energy. This is slow almost by definition.
Directions To Tighten the Loop: Basic Tactics
To shorten the time from opening a code review to merging, we can start with a few basic tactics:
Reduce tool switching
Make it less painful
Make it a habit
Automate code style checking
Reduce Tool Switching
A couple of examples of this tactic:
Integrate your GitHub (GitLab, Bitbucket, etc.) instance with Slack. We use a tool called Axolo. It automatically creates a private Slack channel per pull request. Developers already use Slack, so this integration reduces the friction of switching tools and makes discussions more convenient.
Use editor integrations with the code repository to manage and review pull requests. Most code editors and IDEs have such integrations either built in or available as plugins.
Make It Less Painful
Tasks that require less cognitive energy. are more likely to be done quickly.
A few tactics help a lot:
Prefer smaller pull requests. No one likes reading several thousand lines of someone else’s code. A small, targeted PR is more likely to be picked up quickly.
Describe and annotate PRs. Write a description that explains what the code is doing at a high level — especially what problem it solves and the general approach. Document non-obvious parts.
Make It a Habit
Book one or several time slots in team members’ calendars dedicated to code reviews. For example, 30 minutes in the morning and 30 minutes in the afternoon. It will help team members remember. Also, when time is already allocated, it is easier to justify switching away from one’s own tasks.
Automate Code Style Checking
Code style — such as formatting, documentation, variable naming, and so on — should be checked automatically. Use linters and static code analysis tools to weed out style issues before a human reviewer takes the first pass.
Advanced Tactics
Now let’s go through some advanced methods that go beyond standard SDLC playbooks.
Use AI Reviewers
When we started using the GitHub Copilot code reviewer in early 2025, it didn’t deliver. Most of the comments were about typos and minor nitpicks on particular solutions. Fast-forward to spring 2026: in my experience, Copilot now catches real bugs in code that were missed by self-review and by AI agents. There are similar solutions on the market from other vendors, but I haven’t evaluated them recently and therefore will not speculate further.
Another high-ROI technique is using coding agents for code review. The best approach is to run an AI agent with a clean context, either by clearing the context directly or by using a sub-agent. This increases the chances of detecting bugs and code smells that would be overlooked when reviewing code within the same coding context.
I found that running code reviews multiple times with a clean context gives the best results. One pass usually does not find all the problems and code smells. Two to three passes provide much better results.
In most cases, a CI-integrated agent and multiple passes with a local coding agent give high confidence that the code is in good shape. This leads us to the next point.
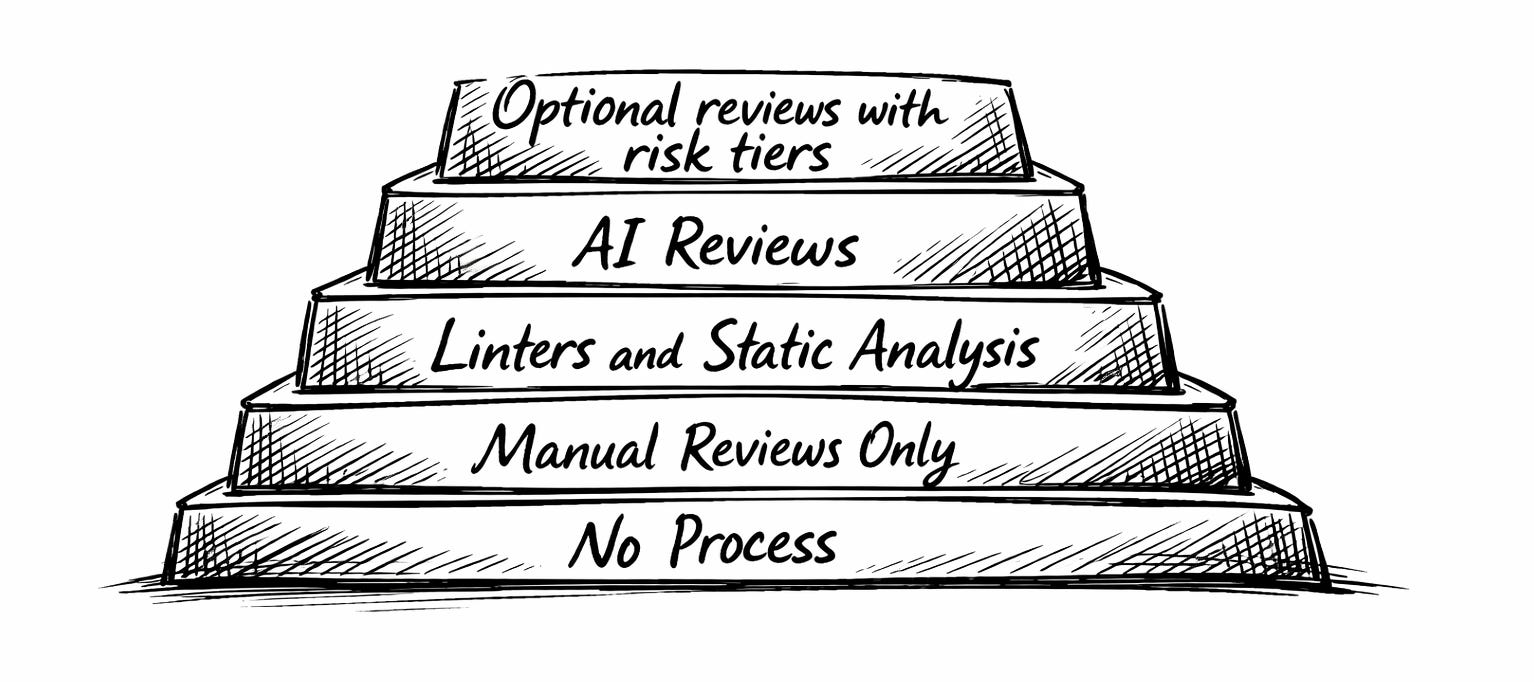
Make Code Reviews Optional
This goes against the widely accepted best practice of blocking code reviews — the convention that requires one or several developers to approve a pull request before it can be merged.
The point of code review is to ensure consistency of the new code with the codebase, validate the change, and spread knowledge within the team.
Let’s go through each of these.
Consistency is the easiest one to address. Linters, formatters, and static analysis tools handle the mechanical side. AI reviewers handle the rest — naming conventions, patterns, architectural alignment. If your team has a well-documented codebase and you’re running an AI reviewer with full context, consistency is largely a solved problem.
Validity — meaning, whether the code actually does what it’s supposed to do, and does it do it correctly — is where human reviewers have traditionally added the most value. A colleague might spot that your solution works on the happy path but fails at the edge case you didn’t think of.
AI reviewers are closing this gap fast. Multiple passes with a clean-context agent catch a surprising number of bugs, logic errors, and missed edge cases. AI review, combined with tests, CI, and the author’s own diligence, is often good enough.
If your test coverage is solid and your CI pipeline is thorough, human involvement in code review may or may not be justified. It depends on the nature of the task, risk tolerance, and the author’s familiarity with the specific system.
In many cases, human code review would not significantly decrease risk but would considerably slow down the development process. In these situations, merging without approval might be a good solution.
Knowledge sharing is the most interesting objection, and the one I take most seriously. The argument is that reviewing each other’s code is how developers on a team stay aligned — understanding what’s being built, how the codebase is evolving, and learning from each other.
However, it is important to distinguish knowledge sharing from blocking. Knowledge can also be distributed through internal RFCs, technical demos, and documentation.
None of this means code reviews should be abolished. For high-stakes changes, a human reviewer is still worth the wait.
As a starting point, human review should still be required for:
High-blast-radius changes
Changes to code with many dependents
Changes in unfamiliar or high-risk parts of the system
Security-sensitive code
Authentication and authorization changes
Billing or financial logic
Data migrations and destructive operations
Core infrastructure and deployment logic
Significant architectural shifts
For lower-risk changes — especially isolated, well-tested work in familiar parts of the codebase — teams should consider making human review optional.
The key shift is that team members can now decide whether they want someone to review their code or whether they feel confident enough to proceed without it.
This shifts the culture from reviews as a gate to reviews as a tool — used deliberately, where they add the most value.
Closing the Loop
Currently, my organization applies all of these tactics, and we have seen a significant increase in development pipeline throughput. Code review queues are often empty or contain only a few items — without sacrificing quality.
Code review bottlenecks are not inevitable. They are a product of habits, tooling, and defaults that made sense in a pre-AI workflow and haven’t been revisited.
Tighten the feedback loop at every level: reduce friction, build habits, automate what can be automated. Then question the assumptions underneath the process itself.
The goal is to ship quality software, shipped fast, by a team that understands what it’s building, why, and for whom. Keep your eye on that.
Thank you for reading, and see you next week,
Roman
P.S. Scaling an engineering org is hard — especially without a sounding board who’s been through it. I spent 20 years building software and then scaled a startup’s engineering department into a top leadership role. I learned management in the trenches, made the mistakes, and figured out what actually works. Today, I help engineering leaders and startup founders stress-test their strategy and scale their teams without repeating those same mistakes.
If you’re facing a challenge — whether it’s org design, technical leadership, or figuring out how to grow from here — drop me a message on LinkedIn.